Tracking mémoire et profiling sur les gros projets
01 Dec 2012J’ai récemment fait l’acquisition d’un superbe T-shirt qui arbore fièrement un logo que vous reconnaîtrez tous :
 Il parait que j'étais le premier client en deux ans. Allez comprendre ?
Il parait que j'étais le premier client en deux ans. Allez comprendre ?C’était donc pour moi une occasion unique de rendre hommage à ce superbe projet et d’y consacrer cet article.
Pour ceux qui n’ont pas reconnu le logo, il s’agit de celui de Valgrind (pourtant c’était écrit gros).
Valgrind est un tracker d’erreur mémoire libre créé par Julian Seward qui a évolué en outil de débogage et de profiling (profilage en français moche) très complet. Le principe de ce logiciel est d’exécuter des programmes dans un environnement virtuel où le processeur est simulé. Ainsi, aucune allocation, affectation, lecture ou libération de mémoire ou même appel de fonction ne lui échappe
Grace à cette architecture Valgrind peut faire les deux choses suivantes de manière redoutablement efficace :
- détecter les erreurs mémoires : il peut vous fournir un rapport complet des dépassements de tableau, des fuites mémoires (perte de pointeur sur une structure non libérée), etc ...
- Faire du profiling : analyse du temps CPU passé dans chaque fonction et le nombre d'appel.
Sur ce dernier point, je précise que le temps comptabilisé est le temps que le processeur virtuel a vraiment consacré à l’exécution du processus. Ce qui rend Valgrind largement supérieur aux autres outils (comme gprof) qui ne peuvent pas tenir compte des interruptions du scheduler pour l’exécution d’autres processus du système. En contrepartie le temps d’exécution réel (vécu par l’utilisateur) est beaucoup plus élevé (jusqu’à 50 fois le temps d’exécution normal).
C’est bien joli tout ça mais pour étudier des logiciels complexes (comme SYNTHESE par exemple) plusieurs problèmes se posent :
- Valgrind est très verbeux :
Les erreurs (et avertissements) mémoire sont toutes détectées, et elles sont toujours nombreuses y compris dans des librairies système dont vous n'êtes même pas l'auteur.
De plus Valgrind s'arrête d'écrire après avoir détecté 100 erreurs. Vous devrez donc souvent augmenter cette limite voir la supprimer. - Valgrind est très verbeux (bis) :
Si la section de code pour laquelle vous soupçonnez une erreur mémoire est exécuté bien après une longue séquence de démarrage, vous serez noyé sous une montagne d'informations inutiles. De même pour le profiling, vous verrez le temps passé dans chaque fonction depuis le démarrage du processus. Un temps qui peut être beaucoup plus long que l'exécution de la fonction qui vous intéresse.
Heureusement pour vous (et pour moi), ces deux problèmes peuvent être réglés grâce à une unique solution : une commande de déclenchement et d’arrêt du tracking.
La méthode diffère en tracking mémoire et en profiling, mais le principe est le même : Il s’agit de lancer Valgrind en mode silencieux (sans aucune analyse ni génération de rapport) puis grâce à un second terminal on désactive le mode silencieux au moment ou on le souhaite (généralement juste avant d’appeller la fonction à tester) puis on l’arrête et on force la génération du rapport.
Les commandes pour le tracking mémoire
valgrind --log-file=mon-fichier.log -v --error-limit=no --vgdb=yes --vgdb-error=0 /chemin/vers/votre/executable -vos -options
Les options importantes dans notre contexte sont
--vgdb=yes et --vgdb-error=0
La première indique que valgrind doit lancer un “pseudo serveur gdb” (je ne rentre pas dans les détails, mais c’est indispensable). La seconde commande à Valgrind de ne pas créer de rapport tant qu’on ne lui aura pas dit le contraire.
Enfin cette option permet de lever la limite du nombre d’erreur loguées dont je parlais en introduction:
--error-limit=no
Ensuite gdb attend un premier contact (je suppose que l’id du process Valgrind est 666):
vgdb --pid=666 v.set vgdb-error 0
Pour lancer les traces:
vgdb --pid=666 v.set vgdb-error 9999999999
Pour voir les erreurs dans avant même d’arrêter Valgrind :
vgdb --pid=666 v.info all_errors > rapport.log
Après ça vous aurez le plaisir de découvrir un sympatique rapport comme ceci :
==11367== Memcheck, a memory error detector.
==11367== Copyright (C) 2002-2007, and GNU GPL'd, by Julian Seward et al.
==11367== Using LibVEX rev 1804, a library for dynamic binary translation.
==11367== Copyright (C) 2004-2007, and GNU GPL'd, by OpenWorks LLP.
==11367== Using valgrind-3.3.0-Debian, a dynamic binary instrumentation framework.
==11367== Copyright (C) 2000-2007, and GNU GPL'd, by Julian Seward et al.
==11367== For more details, rerun with: -v
==11367==
1
99
==11367== Invalid read of size 1
==11367== at 0x804888F: bigint_add (math.c:34)
==11367== by 0x8048A25: main (test.c:17)
==11367== Address 0x4185069 is 0 bytes after a block of size 1 alloc'd
==11367== at 0x4022AB8: malloc (vg_replace_malloc.c:207)
==11367== by 0x804850B: bigint_cont_alloc (memory.c:13)
==11367== by 0x8048636: bigint_set (memory.c:63)
==11367== by 0x80489BB: main (test.c:6)
==11367==
==11367== Invalid free() / delete / delete[]
==11367== at 0x402265C: free (vg_replace_malloc.c:323)
==11367== by 0x80487F2: resize_cont (math.c:13)
==11367== by 0x8048956: bigint_add (math.c:45)
==11367== by 0x8048A25: main (test.c:17)
==11367== Address 0x4185158 is 0 bytes inside a block of size 2 free'd
==11367== at 0x4022B8E: realloc (vg_replace_malloc.c:429)
==11367== by 0x80487D2: resize_cont (math.c:8)
==11367== by 0x8048956: bigint_add (math.c:45)
==11367== by 0x8048A25: main (test.c:17)
...
encore beaucoup de lignes
Les commandes pour le profiling
valgrind --tool=callgrind --dump-instr=yes --simulate-cache=yes --collect-jumps=yes --instr-atstart=no ./executable
Cette fois-çi l’option importante c’est :
--instr-atstart=no
Elle indique que Valgrind ne doit pas créer de rapport tant qu’on ne lui aura pas dit le contraire.
Puis pour déclencher le démarrage du profiling en remote, on lance dans un second terminal :
callgrind_control -i on
Et pour couper c’est off (intuitif non).
Si vous n’êtes pas en mesure de déclencher manuellement le tracking parce que vous ne pouvez pas prévoir quand votre code sera appelé ou parce que vous n’avez pas les réflexes suffisamment affutés il vous reste une solution : Instrumenter votre code avec des macros du genre :
Vous aurez remarqué l’option tool=callgrind qui permet de sélectionner l’outil qui réalise la sortie. Callgrind génére un fichier que vous pouvez ouvrir avec kcachegrind pour explorer les appels graphiquement :
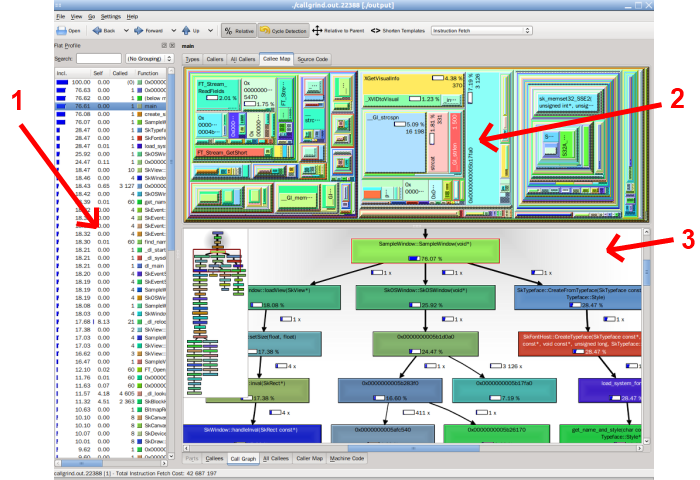
Zone 1 : la liste des fonctions appelées triées par temps passé, qui indique aussi le nombre d’appel
Inutile de passer trop de temps à optimiser une fonction dans laquelle on ne passe que 0,00008% de temps cumulé.
Zone 2 : cartographie des appels : l’aire représente le temps passé dans la fonction (change en fonction de la sélection)
Zone 3 : le graphe des appels et des appelants d’une fonction (change en fonction de la sélection)
C’est très confortable pour le profiling et ça impressionne les collègues de passage qui font du Java ou du Oracle.
Conclusion
Elle est pas belle la vie ?
Avec les commandes ci-dessus j’ai pu effectuer des interventions sur des fonctions très précises dans SYNTHESE qui est pourtant un gros process multi-thread avec une séquence de démarrage complexe. Par contre vu la lenteur d’exécution de valgrind j’ai souvent démarré mon process le soir pour attaquer mon travail de débogage et de profiling le matin.
Nous avons aussi la chance d’avoir très peu d’erreurs mémoire dans SYNTHESE comparé à la taille du projet, grace à un framework rigoureux et à une utilisation massive des pointeur intelligent Boost.
D’expérience je peux vous dire que les premières exécutions de valgrind sur un logiciel réservent bien des surprises. Cela est d’autant plus embarrassant que la documentation de Valgrind précise que les erreurs doivent impérativement êtres corrigées (MUST BE FIXED) sauf cas très rares (si on fait des déplacements de pointeur en calculant les adresses par exemple) car ce sont de véritables erreurs qui pourraient avoir des conséquence en production. Par exemple des “Conditionnal jump on uninitialized value” peuvent ne pas avoir de conséquence avec certains compilo ou OS mais en avoir sur d’autres.
Pour plus d’information sur les options de valgrind je vous invite à lire le f… manuel.